TensorFlow学习笔记7:卷积神经网络
目标
用Tensorflow实现一个完整的卷积神经网络,用这个卷积神经网络来识别手写数字数据集(MNIST)。
网络结构
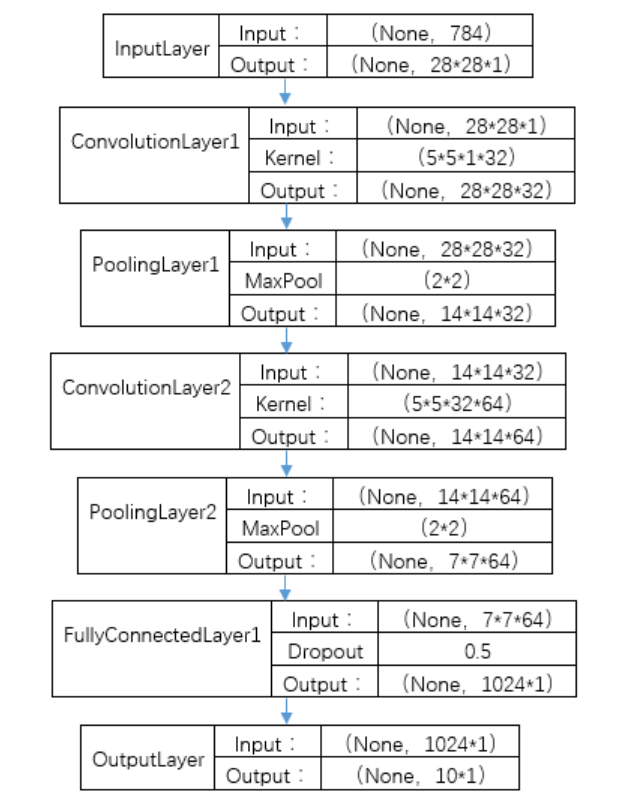
TensorFlow实现
导入模块
1
import tensorflow as tf
导入MINIST数据集
1
2
3from tensorflow.examples.tutorials.mnist import input_data
# number 1 to 10 data
mnist = input_data.read_data_sets("MNIST_data",one_hot=True)
定义Weight和Bias参数
定义产生Weight参数的函数,传入shape,返回Weight参数。
1
2
3def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)定义产生Bias参数的函数,传入shape,返回Bias参数。
1
2
3def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
定义卷积和池化操作
定义卷积操作。tf.nn.conv2d函数是Tensorflow里面的二维的卷积函数,x是图片的所有参数,W是卷积层的权重,然后定义步长strides=[1,1,1,1]值。strides[0]和strides[3]的两个1是默认值,意思是不对样本个数和channel进行卷积,中间两个1代表padding是在x方向运动一步,y方向运动一步,padding采用的方式实“SAME”就是0填充。
1
2
3
4def conv2d(x, W):
# stride[1, x_movement, y_movement, 1]
# Must have strides[0] = strides[3] =1
return tf.nn.conv2d(x, W, strides=[1,1,1,1], padding="SAME") # padding="SAME"用零填充边界定义池化操作。为了得到更多的图片信息,卷积时我们选择的是一次一步,也就是strides[1]=strides[2]=1,这样得到的图片尺寸没有变化,而我们希望压缩一下图片也就是参数能少一些从而减少系统的复杂度,因此我们采用pooling来稀疏化参数,也就是卷积神经网络中所谓的下采样层。pooling有两种,一种是最大值池化,一种是平均值池化,我采用的是最大值池化tf.max_pool()。池化的核函数大小为2*2,因此ksize=[1,2,2,1],步长为2,因此strides=[1,2,2,1]。
1
2def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1,2,2,1], strides=[1,2,2,1], padding="SAME")
输入处理
定义输入的placeholder
1
2
3# define placeholder for inputs to network
xs = tf.placeholder(tf.float32, [None,784]) # 28*28
ys = tf.placeholder(tf.float32, [None,10])定义dropout的placeholder,它是解决过拟合的有效手段。
1
2# 定义dropout的输入,解决过拟合问题
keep_prob = tf.placeholder(tf.float32)处理xs输入
1
2
3
4# 处理xs,把xs的形状变成[-1,28,28,1]
# -1代表先不考虑输入的图片例子多少这个维度。
# 后面的1是channel的数量,因为我们输入的图片是黑白的,因此channel是1。如果是RGB图像,那么channel就是3.
x_image = tf.reshape(xs, [-1, 28, 28, 1])
建立卷积层
第一层卷积层
1
2
3
4W_conv1 = weight_variable([5,5,1,32]) # kernel 5*5, channel is 1, out size 32
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image,W_conv1) + b_conv1) # output size 28*28*32
h_pool1 = max_pool_2x2(h_conv1) # output size 14*14*32第二层卷积层
1
2
3
4W_conv2 = weight_variable([5,5,32,64]) # kernel 5*5, in size 32, out size 64
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1,W_conv2) + b_conv2) # output size 14*14*64
h_pool2 = max_pool_2x2(h_conv2) # output size 7*7*64
建立全连接层
展平输出。我们通过tf.reshape()将h_pool2的输出值从一个三维的变为一个一维的数据,-1表示先不考虑输入图片例子维度,将上一个输出结果展平。
1
2# [n_samples,7,7,64]->>[n_samples, 7*7*64]
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])全连接层
1
2
3W_fc1 = weight_variable([7*7*64, 1024])
b_fc1 = bias_variable([1024])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)同时考虑了过拟合的问题,可以加一个dropout的处理。
1
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
输出层
输出层参数,输入为1024,输出为10。
1
2W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])softmax分类器
1
prediction = tf.nn.softmax(tf.matmul(h_fc1_drop,W_fc2)+b_fc2)
优化方法
交叉熵损失函数
1
2# the error between prediction and real data
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction),reduction_indices=[1]))优化器
tf.train.AdamOptimizer()优化器
1
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
tf.train.GradientDescentOptimizer()优化器
1
train_step = tf.train.GradientDescentOptimizer(1e-4).minimize(cross_entropy)
训练过程
定义session,初始化变量
1
2
3sess =tf.Session()
# important step
sess.run(tf.initialize_all_variables())训练1000次,每50次检查模型精度
1
2
3
4
5
6for i in range(1000):
batch_xs,batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={xs:batch_xs,ys:batch_ys, keep_prob:0.5})
if i % 50 ==0:
# print(sess.run(prediction,feed_dict={xs:batch_xs}))
print(compute_accuracy(mnist.test.images,mnist.test.labels))
完整代码
1 | #coding:utf-8 |