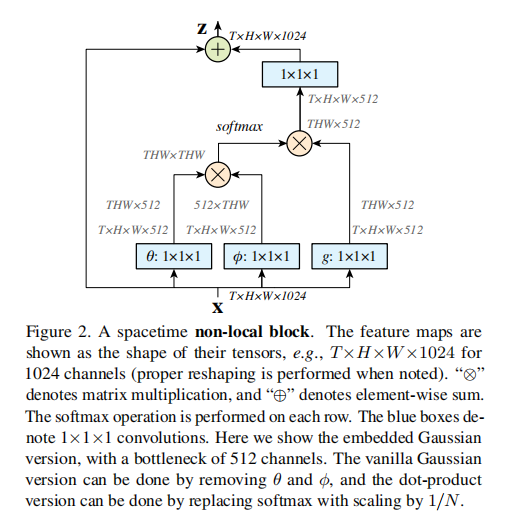
Non-local PyTorch部分源码解读 发表于 2019-08-13 分类于 深度学习 , Python Valine: 本文字数: 4k 代码地址:https://github.com/AlexHex7/Non-local_pytorch 前言我只看了non-local_embedded_gaussian.py文件下的源码,以下为我的解读 结构图示 部分代码解读123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119class _NonLocalBlockND(nn.Module): ''' in_channels为输入的通道数 inter_channels为中间过程的通道数 dimension为维度数 sub_sample标志是否进行下采样(subsampled) bn_layer标示是否进行Batch Norm ''' def __init__(self, in_channels, inter_channels=None, dimension=3, sub_sample=True, bn_layer=True): # assert用来检查条件,不符合就终止 # 只能处理一维,二维以及三维的输入数据 assert dimension in [1, 2, 3] self.dimension = dimension self.sub_sample = sub_sample self.in_channels = in_channels self.inter_channels = inter_channels # 若没有指定中间过程的通道数,则指定为输入通道数的一半 if self.inter_channels is None: self.inter_channels = in_channels // 2 if self.inter_channels == 0: self.inter_channels = 1 # 根据输入的维数来指定对应的卷积函数,池化函数以及归一化函数 if dimension == 3: conv_nd = nn.Conv3d max_pool_layer = nn.MaxPool3d(kernel_size=(1, 2, 2)) bn = nn.BatchNorm3d elif dimension == 2: conv_nd = nn.Conv2d max_pool_layer = nn.MaxPool2d(kernel_size=(2, 2)) bn = nn.BatchNorm2d else: conv_nd = nn.Conv1d max_pool_layer = nn.MaxPool1d(kernel_size=(2)) bn = nn.BatchNorm1d # 指定g函数 self.g = conv_nd(in_channels=self.in_channels, out_channels=self.inter_channels, kernel_size=1, stride=1, padding=0) # 判断是否需要进行归一化操作 if bn_layer: self.W = nn.Sequential( conv_nd(in_channels=self.inter_channels, out_channels=self.in_channels, kernel_size=1, stride=1, padding=0), bn(self.in_channels) ) nn.init.constant(self.W[1].weight, 0) nn.init.constant(self.W[1].bias, 0) else: self.W = conv_nd(in_channels=self.inter_channels, out_channels=self.in_channels, kernel_size=1, stride=1, padding=0) # 初始化为0 nn.init.constant(self.W.weight, 0) nn.init.constant(self.W.bias, 0) self.theta = conv_nd(in_channels=self.in_channels, out_channels=self.inter_channels, kernel_size=1, stride=1, padding=0) self.phi = conv_nd(in_channels=self.in_channels, out_channels=self.inter_channels, kernel_size=1, stride=1, padding=0) # 判断是否需要进行下采样 if sub_sample: self.g = nn.Sequential(self.g, max_pool_layer) self.phi = nn.Sequential(self.phi, max_pool_layer) def forward(self, x): ''' :param x: (b, c, t, h, w) :return: ''' # 获得batch的大小 batch_size = x.size(0) # g(x)的size为batch_size*inter_channels*W*H # view类似于resize,使得个g_x的size为batch_size*inter_channels*(W*H) g_x = self.g(x).view(batch_size, self.inter_channels, -1) # 维度换位,g_x的size变成batch_size*(W*H)*inter_channels g_x = g_x.permute(0, 2, 1) # theta_x的size为batch_size*inter_channels*(W*H) theta_x = self.theta(x).view(batch_size, self.inter_channels, -1) # theta_x的size为batch_size*(W*H)*inter_channels theta_x = theta_x.permute(0, 2, 1) # phi_x的size为batch_size*inter_channels*(W*H) phi_x = self.phi(x).view(batch_size, self.inter_channels, -1) # f的size为batch_size*(W*H)*(W*H) f = torch.matmul(theta_x, phi_x) f_div_C = F.softmax(f, dim=-1) # y的size为batch_size*(H*W)*inter_channels y = torch.matmul(f_div_C, g_x) # view只能用在contiguous的variable上。如果在view之前用了transpose, permute等, # 需要用contiguous()来返回一个contiguous copy。 # y的size为batch_size*inter_channels*(H*W) y = y.permute(0, 2, 1).contiguous() # y的size为batch_size*inter_channels*H*W y = y.view(batch_size, self.inter_channels, *x.size()[2:]) # W_y的size为batch_size*out_channels*W*H W_y = self.W(y) # 得到最终输出 z = W_y + x return z