论文阅读笔记9:Scale-Aware Trident Networks for Object Detection
论文地址:https://arxiv.org/pdf/1901.01892
代码地址:https://github.com/TuSimple/simpledet/tree/master/models/tridentnet
Abstract
尺度变换是目标检测中的关键挑战。在我们的工作中,我们首先提出了一个控制的实验来研究感受野在检测不同尺寸物体上的影响。基于探索实验的发现,我们提出了一个全新的Trident Net-work (TridentNet),可以生成具有统一表征能力的特定尺度的feature map,我们构建了一个平行的多分支结构,在每一个分支中分享相同的转换参数,但是具有不同的感受野。然后,我们提出了一种规模感知的训练模式来,通过采样适当比例的对象实例来训练每一个分支。在COCO数据集中,我们的以ResNet-101作为特征提取网络的TridentNet获得了当前最先进的单一模型的结果,48.4的mAP。
Introduction
CNN-based方法可以粗略的分为两类:
- one stage method 直接使用前馈神经网络来预测边界框
- two stage method 先生成proposals,然后利用经过CNN提取的区域特征进行更好的refinement
然而,两种方法的一个中心问题就是怎么处理尺度变换。我们都知道物体的尺寸在很大的范围内变化,这会阻碍检测器的性能,尤其是那些很小或者很大的物体。
为了补救尺度变化的问题:
- image pyramids
从非Deep时代,乃至CV初期就被就被广泛使用的方法叫做image pyramid。在image pyramid中,我们直接对图像进行不同尺度的缩放,然后将这些图像直接输入到detector中去进行检测。虽然这样的方法十分简单,但其效果仍然是最佳,也后续启发了SNIP这一系列的工作。单论性能而言,multi-scale training/testing仍然是一个不可缺少的组件。然而其缺点也是很明显的,测试时间大幅度提高,对于实际使用并不友好。 - feature pyramids
另外一大类方法,也是Deep方法所独有的,也就是feature pyramid。最具代表性的工作便是经典的FPN了。这一类方法的思想是直接在feature层面上来近似image pyramid。非Deep时代在检测中便有经典的channel feature这样的方法,这个想法在CNN中其实更加直接,因为本身CNN的feature便是分层次的。从开始的MS-CNN直接在不同downsample层上检测大小不同的物体,再到后续TDM和FPN加入了新的top down分支补充底层的语义信息不足,都是延续类似的想法。然而实际上,这样的近似虽然有效,但是仍然性能和image pyramid有较大差距。
image pyramids以及feature pyramids的motivation都是一样的,即模型对不同的尺度的object需要具有不同的感受野。尽管并不高效,但image pyramids充分的利用模型的表征能力来平等的转换所有尺寸的objects。而feature pyramids生成多尺度的features因此牺牲了features在不同尺度的一致性。我们的工作的目标就是为所有尺度有效的创建具有统一表征能力的features来获得最好的效果。
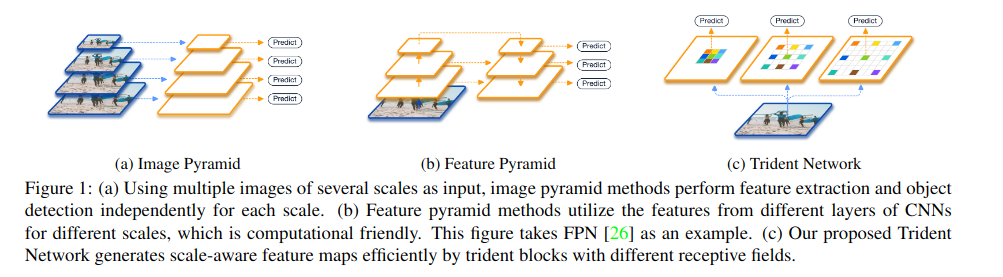
在本文中,我们提出了一个全新的网络结构来适应不同尺寸的网络。特别的,我们通过上图所示的trident blocks,创造了多个尺度特定的feature maps。得益于空洞卷积,trident blocks的不同分支有着同样的网络结构,并且共享同样的权重参数,但是又不同的感受野。另外,为了避免训练具有极端尺寸的objects,我们采用尺度感知的训练模式,使每个分支给定的尺度范围与其感受野相匹配。最终,得益于整个多分支网络之间的权值共享,我们可以在inference的过程中通过一个主要的分支来估计整个TridentNet。这种估计只会带来边际性能的下降(不太懂)。最终,它能够在单尺度的baseline上达到显著地提升,而不需要对inference的速度做出任何妥协。
总结我们的贡献如下:
- 我们提出了我们关于在不同尺度的objects上的感受野的影响。我们是是第一个通过设计控制实验来探索目标检测任务的感受野。
- 我们提出了一个全新的Trident Network来处理目标检测上的尺度变换问题。通过多分支的结构以及尺度感知的训练,TridentNet能够通过统一的表征能力生成尺度特定的feature maps。
- 得益于我们的权重共享的trident-bloc的设计,我们提出了一种通过主要分支来进行快速的估计的方法。因此可以在inference期间不引入额外的参数以及计算成本。
- 我们通过ablation studies在标准的COCO benchmark上验证了我们的方法的高效性。与最先进的方法相比,我们提出的方法获得了显著地性能。
Related Work
Deep Object Detectors
Methods for handling scale variation
Dilated convolution
Investigation of Receptive Filed
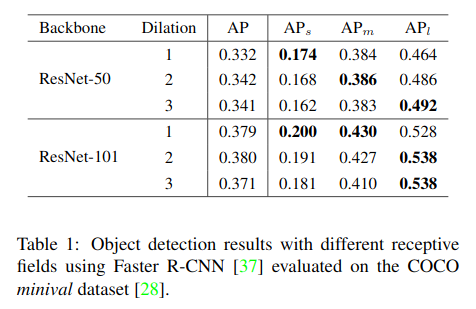
可能影响目标检测器的性能的一些关于backbone网络的因素有:下采样率,网络深度以及感受野。一些工作已经讨论了它们的影响。前两个因素的影响是很直观的:网络越深(或叫表示能力更强)结果会越好,下采样次数过多对于小物体有负面影响。据我们所知,先前没有工作单独研究感受野对检测器性能的影响。
为了研究感受野对检测不同尺度的物体的影响,我们将backbone网络中的一些卷积操作替换为dilated variant。我们使用不同的dilation rates来控制网络的感受野。
我们在COCO benchmark上使用Faster R-CNN检测器来进行这个试验性实验。我们使用ResNet-50以及ResNet-101作为backbone网络,并且将conv4层的残差模块的3*3卷积操作的dilation rate$d_s$在1和3之间变化。
下表总结了在不同dilation rates下的检测结果。我们可以发现随着感受野的扩大,检测器对检测小物体的性能持续下降。但是对于大物体,则可以从不断增加的感受中受益。以上的发现可以总结如下:
- 对不同尺寸物体的检测的性能受网络感受野的影响。最合适的感受野与objects的尺寸紧密相关。
- 尽管ResNet-101有理论上足够大的感受野来覆盖COCO上有着大尺寸的objects,但检测大物体的性能仍然可以通过增加dilation rate来提升。在小物体上也同样如此。我们猜测检测网络高效的感受野需要平衡物体的大小尺寸。
Trudent Network
我们提出的TridentNet主要包括权重共享的trident blocks以及尺度感知训练模式。
Network Structure
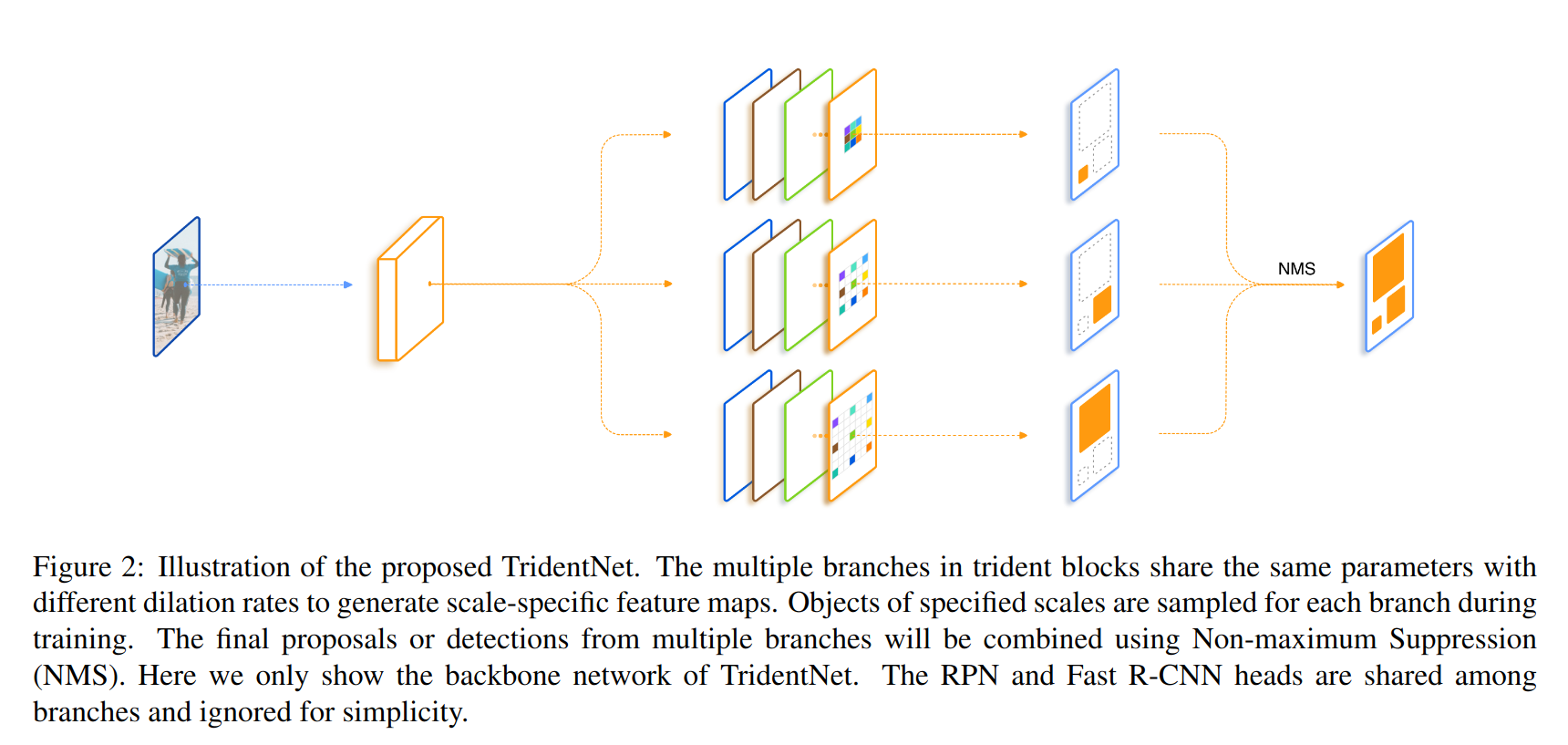
我们的方法以单一尺度的图片作为输入,然后产生尺度特定的feature maps通过平行的分支,即有着相同的参数但是dilation rates不同的卷积。
- Multi-branch Block
我们通过将原backbone中的一些卷积块替换为trident blocks来构建TridenNets。每一个trident blocks都由多个平行的分支组成。
以ResNet为例。对于一个bottleneck样式的残差模块,由三个卷积核大小分别为1*1,3*3,1*1的卷积组成。其对应的trident block由多个平行的有着不同dilation rates的3*3卷积的残差模块构成。堆叠的trident blocks允许我们以一种高效的方式调节不同分支的感受野。通常我们将trident block应用在最后一层的blocks,因为较大的stride会导致需要的感受野有较大的差异。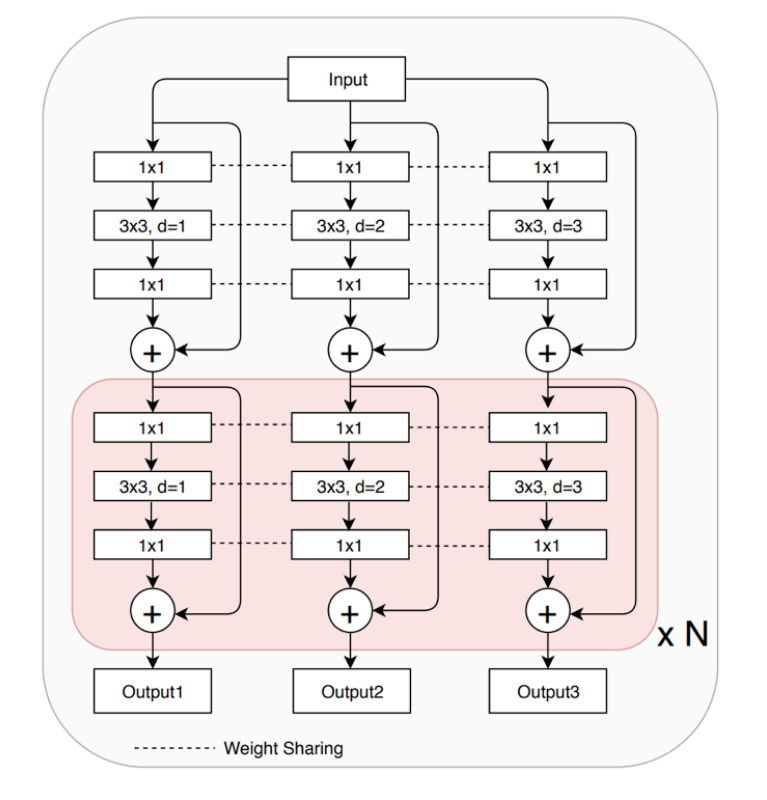
- Wight sharing among branches
TridentNet不同分支之间的权重参数都是共享的,只是dilation rates有所不同。这种设置使得权重的共享更加简单直接。
权重共享有三大优势:- 减少了参数的数量,与原始目标检测器相比,并没有额外增加参数数量。
- 与我们的motivation相呼应,即不同尺度的物体应该在相同表征力下进行统一的转化。
- 转换参数可以针对来自所有分支的更多对象样本进行训练,换句话说就是在不同感受野下对不同尺寸范围训练相同的参数。
Scale-aware Training Scheme
我们提出的trident结构根据预定义的ddilation rates生成尺度特定的feature maps。然而在么一个单一分支中仍然存在尺寸的错误匹配。因此我们提出了一种尺度感知训练模式来提升每一个分支的尺度感知能力,避免在不匹配的分支上出现极端尺度的训练对象。
类似于SNIP,我们为每一个分支$i$定义一个有效区域$[l_i,u_i]$。在训练过程中,我们只选择那些尺寸落在每个分支对应的有效分区的proposals以及真实框。特别的,对于一个长为$h$宽为$w$的Region-of-Interest (ROI),若它在分支$i$有效,则:
这个尺度感知的训练模式会被应用到RPN以及R-CNN。在我们的尺度感知训练中,在RPN分配anchor标签时,我们选择根据上述公式在该分支有效的ground truth boxes。相似的,我们在R-CNN的训练过程中,在每个分支上采样有效的proposals。
Inference and Approximation
在inference期间,我们在所有分支上生成生成检测结果,然后滤除落在每个分支有效范围外的boxes。我们然后采用NMS或者soft-NMS结合多个分支的的输出来得到最终的结果。
Fast Inference Approximation
为了加速我们的网络的inference速度,在inference过程中,我们可以只使用一个主要的分支来作为对TridentNet估计。特别的,我们将其有效范围设置为$[0,\infty]$来预测所有尺度的objects。对于如上图所示的三分支网络,我们使用中间分支作为我们的主要分支,因为它的有效范围涵盖了大物体以及小物体。在这种方式下,我们的fast TridentNet相比于传统的Faster R-CNN检测器没有额外的时间损耗。令人吃惊的是,我们发现这种估计相比于原来的TridentNet只有轻微的性能下降。
Experiments
Implementation Details
我们在MXNet上重新实现Faster R-CNN,来作为我们的baseline method。我们将ResNet中的conv4层的输出作为backbone feature map,并且con5阶段作为rcnn head。对于每一张图,我们在每个分支上采样128个ROIs。我们使用三个分支作为我们的默认结构。在三个分支上的dilated rates分别设置为1,2,3。三个分支上的有效范围分别设置为$[0,90]$,$[30,160]$,$[90,\infty]$。
Ablation Studies
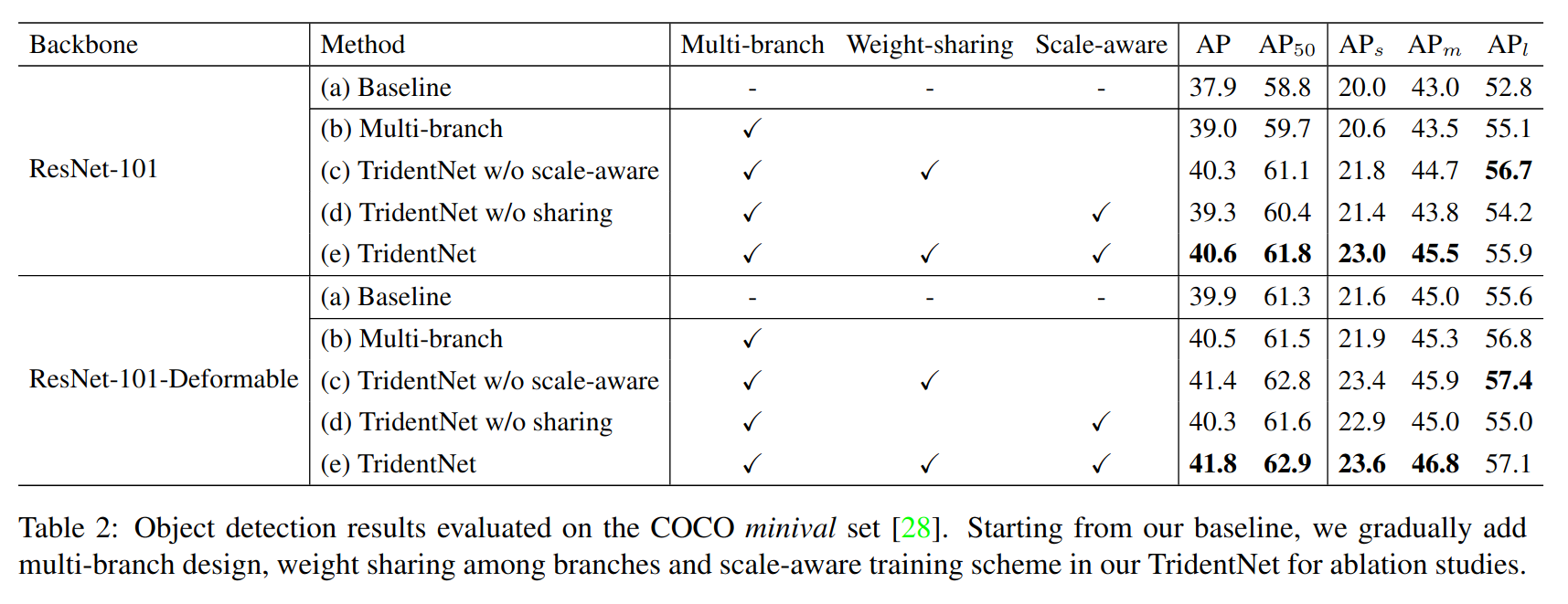
Components of TridentNet
- Multi-branch
- Scale-aware
- Weight-sharing
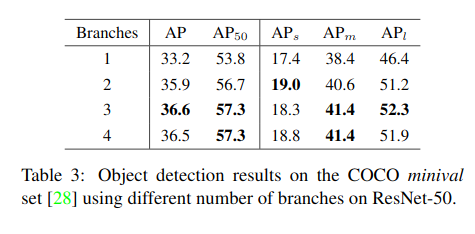
Number of branches
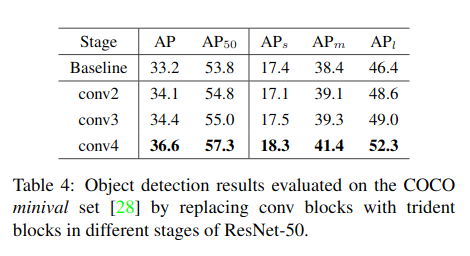
Stage of Trident blocks
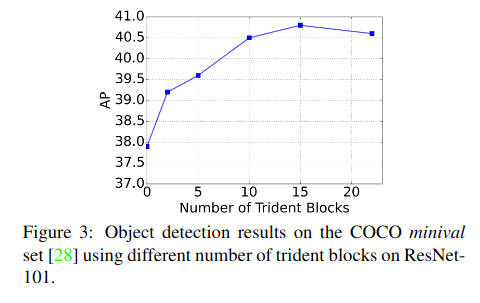
Number of trident blocks
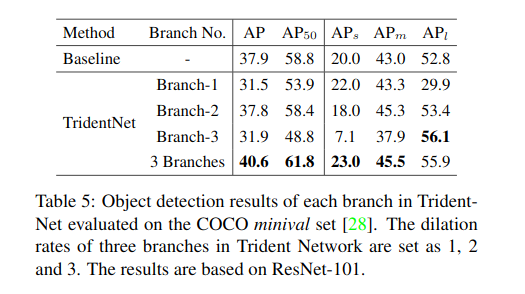
Perfomance of each branch
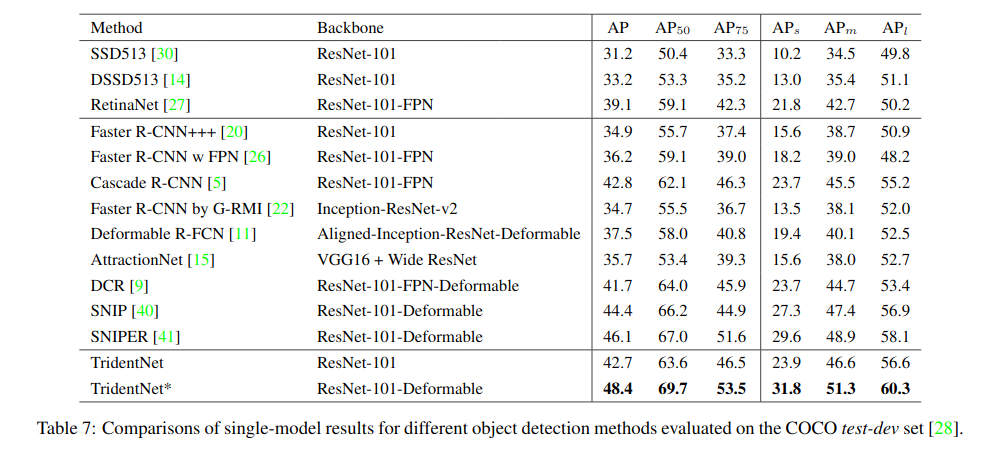
Comparision with State-of-the-Arts
Fast approximation
- the three-branch methods 42.7/48.4 AP
- the major branch 42.2/47.6 AP
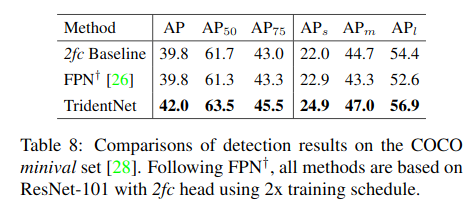
Compare with FPN
Conclusion
在本文中,我们提出了一个简单的目标检测方法TridentNet来通过相同的表征能力在网络中构建尺寸特定的的feature maps。对于我们的多分支结构,我们提出了尺度感知的训练模式为每个分支分配对应的尺度。使用主要分支的fast inference方法使得TridentNet在baseline上得到显著的提升,而不需要额外的参数和计算。我们相信TridentNet有益于当前的目标检测以及其他视觉任务。我们会在未来的工作中探索这个方向。