论文阅读笔记8:Non-local Neural Networks
论文地址:https://arxiv.org/abs/1711.07971v3
代码地址:https://github.com/facebookresearch/video-nonlocal-net
Abstract
不论是卷积网络还是递归网络,它们都是作用在某一块局部区域(local neighborhood)的operations。在本文中,我们提出了non-local operations作为一种通用的神经网络的building blocks来捕捉基于long-range的依赖关系。受到经典的non-local means方法的启发,本文的non-local operation会将某一位置的响应当做是一种从特征图谱所有位置的加权和来计算。该building block可以插入到现在计算机视觉的许多模型当中,进而可以提升分类,检测,分割等视觉任务的性能表现。
Introduction
捕获long-range dependencies在深度神经网络中具有重要意义。对于图片数据,long-distance dependencies以深度堆叠的卷积网络形成的更大的感受野为模型。
不管是卷积操作还是recurrent操作都是在空间或者时间的local neighborhood上进行的;因此long-rangedependencies只能通过重复执行这些操作,通过数据逐步传递信号来得到。重复的local操作有一些限制:
- 它的计算很低效
- 它导致了需要认真对待的优化困难
- 这些challenges make multi-hop dependency modeling,比如较远的两个位置之间的信息前向和反向传播会比较困难(这段没看懂)
本文中,我们提出了non-local操作,来作为一个在深度神经网络中的高效,简单以及通用的组件老捕捉long-range dependencies。我们提出的non-local操作源自计算机视觉中经典的non-local mean操作。我们的non-local操作计算一个位置的响应作为输入的feature map上的所有位置的加权和来计算。这些位置可以在空间,时间或者时空中,所以我们的操作适用于图片,序列以及视频问题。
使用non-local的一些优点:
- 相比于 CNN 和 RNN 的逐步计算的劣势, non-local 操作 可以直接从任意两点中获取到 long-range dependencies.
- 根据实验结果可知, non-local operations 是十分高效的, 并且即使在只有几层网络层时, 也能取得很好的效果.
- 最后, 本文的 nocal operaions 会维持输入变量的尺寸大小, 并且可以很容易的与现有的其他 operations 结合使用.
我们用 video classification 任务来展示 non-local 的有效性. 在视频数据中, long-range interactions 不仅出现在 空间位置上的 distant pixels, 还会出现在时间维度上的 distant pixels. 通过一个单一的 non-local block (basic unit), 以前馈的方式,便可以捕获到这些 spacetime dependencies, 如果将多个 non-local block 组合起来形成 non-local neural networks, 便可以提高 video classification 任务的准确度(不加任何tricks). 另外, non-local 网络要比 3D 卷积网络的计算性价比更高. 为了说明 non-local 的一般性, 我们还在 COCO 数据集上进行了目标检测/分割, 姿态识别等任务的实验, 在基于 MaskRCNN 的网络基础上, 我们的 non-local blocks 可以用较少的计算开销进一步提升模型的精度.
Related Work
Non-local image processing
Graphical models
Feedforward modeling for sequences
Self-attention
Interaction networks
Video classification architectures
Non-local Neural Network
下面首先给出 non-local operations 的一般性定义, 然后会给出几种特定的变体
Formulation
遵循non-local mean操作,我们定义了一个在深度神经网络中通用的non-local操作:
上式中,$i$代表了output中计算响应的位置的index,而$j$枚举了所有可能的position。x是input signal(一般为特征图谱),y是output signal(与x的size相同)。f会返回一个标量(表示i与j之间的relationship),g也会返回一个标量,代表在j位置上的input signal。通过系数$C(x)$对响应进行归一化。
该公式的 non-local 特性主要体现在考虑了所有可能的 position (∀j), 而卷积网络只会考虑 output position 周围位置的像素点。
non-local操作不同于全连接层。non-local计算的响应是基于不同位置之间的relationship,而全连接层使用的是学习的权重。换句话说,在全连接层中,$x_i$和$x_j$之间的relationship并不是input data的函数。另外,我们的公式支持不同的输入尺寸,同时在输出中保留对应的尺寸。
non-local是一个非常灵活的模块, 它可以被添加到深度神经网络的浅层网络当中去(不像fc那样处于深层网络), 这使得我们可以构建更加丰富的模型结构来结合non-local和local信息。
Instantiations
接下来我们介绍介个不同版本的$f$函数以及$g$函数。我们会在实验中证明我们的non-local模型对这些函数的选择并不敏感。 这意味着non-local的通用性正是提升各个模型在不同任务上性能表现的主要原因。
出于简洁,我们把$g$函数考虑成线性形式:$g(x_i)=W_g*x_j$,$W_j$是个需要被学习的权重矩阵,在实现时,通常会通过1×1(或 1×1×1)的卷积来实现。
接下来我们讨论$f$函数的选择:
Gaussian
一个最自然的选择就是高斯函数:这里$x_i^Tx_j$为两个向量的点积,会返回一个标量,有时候也可以使用欧几里得距离,不过点积的实现更加容易。归一化参数为$C(x)=\sum_{\forall j}f(x_i,x_j)$。
Embedded Gaussian
高数函数的一个简单拓展就是在embedding space中计算相似度:其中$\theta(x_i)=W_\theta x_i$,$\phi(x_j)=W_\phi x_j$为两个embeddings。和上述一样,我们设定$C(x)=\sum_{\forall j}f(x_i,x_j)$。
我们发现self-attention模块其实就是non-local的embedded Gaussian版本的一种特殊情况。对于给定的$i$,$\frac{f(x_i,x_j)}{C(x)}$就变成了计算所有的$j$的softmax,即$y=softmax(x^T W_\theta^T W_\phi x)g(x)$,这就是self-attention的表达形式。这样我们就将self-attention模型和传统的非局部均值联系在了一起,并且将sequential self-attention network推广到了更具一般性的space/spacetime non-local network,可以在图像、视频识别任务中使用。Dot produt
$f$也可以定义为点乘相似度:这里我们采用embedded版本。在这种情况中,我们设置归一化参数$C(x)=N$,$N$为在$x$中的所有位置的个数,而不是$f$之和,因为这样能够简化梯度计算。这种形式的归一化是有必要的,因为输入的size是变化的,所以用x的size作为归一化参数有一定道理。
dot product和embeded gaussian的版本的主要区别在于是否做softmax,softmax在这里的作用相当于是一个激活函数。Concatenation
Concatenation是在Relation Network中使用的pairwise function。于是我们也设计了一个concatenation版本的$f$:这里中括号中的代表concatenation,$w_f$是能够将concatenation向量转化为一个标量的权重向量。这里设置$C(x)=N$。
以上我们定义了多种变种,这说明了我们的non-local操作的灵活性,我们相信也会有别的变种能够提升性能。
Non-local Block
我们将上面介绍的公式(non-local operation)包装进一个 non-local block 中, 使其可以整合到许多现有的网络结构当中, 我们将 non-local 定义成如下格式:
$y_i$由上述公式得到,“$+x_i$”代表一个残差连接。残差连接使得我们可以将一个新的non-local block插入一个预先训练好的模型,而不会破坏其原有的结构(如$W_z=0$作为初始化则完全和原始结构一致)。下图演示了一个non-local block。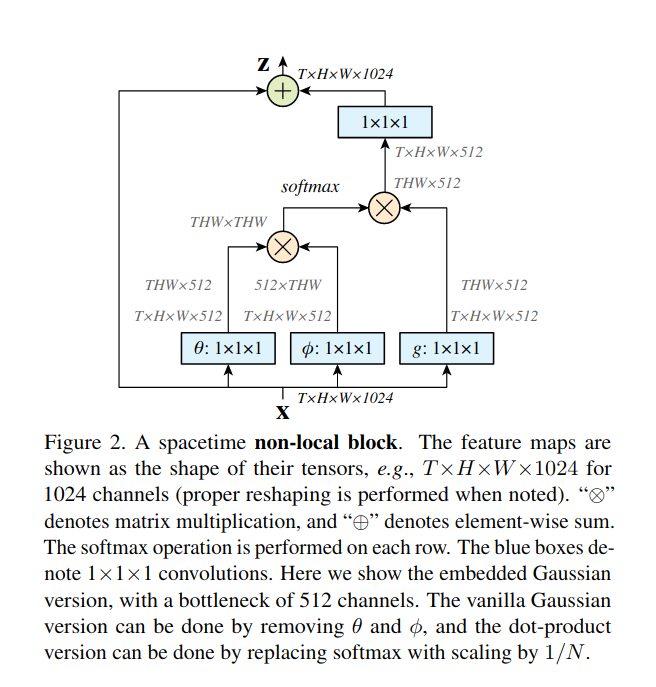
non-local block的pairwise的计算可以是非常轻量级的,如果它用在高层级,较小的feature map上的话。比如,图2上的典型值是T=4,H=W=14 or 7。通过矩阵运算来计算parwise function的值就和计算一个conv layer的计算量类似。另外我们还通过以下方式使其更高效。
- Implementation of Non-local Blocks
我们设置 $W_g$,$W_\theta$,$W_\phi$的通道数为$x$通道数目的一半,这样就形成了一个bottleneck,就能够减少一半的计算量。$W_z$再重新放大到$x$的通道数目,以保证输入输出维度一致。
还有个下采样的trick可以进一步采用,就是将non-local的公式改为$y_i=\frac{1}{C(\hat{x})}\sum_{\forall j}f(x_i,\hat{x}_j)g(\hat{x}_j)$,其中$\hat{x}_j$是$x_j$下采样得到的,比如通过pooling。我们将这个方式在空间域上使用,可以减少1/4的pairwise function的计算量。这个trick髌骨会改变non-local的行为,而是使计算变得稀疏了。可以通过在上图中的$\phi$以及$g$后面增加一个max pooling层来实现。
Video Classification Models
没看
Experiments on Video Classification
没看
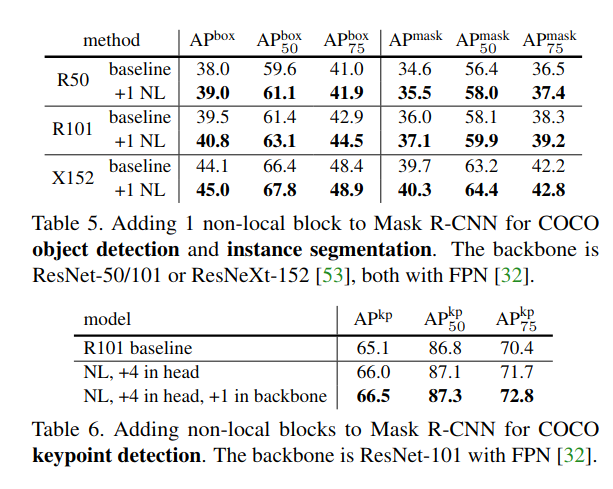
Extension:Experiments on COCO
Conclusion
我们提出了一种新的神经网络,能够通过non-local操作捕捉 long-range dependencies。我们的non-local blocks能够与任何已存在的结构结合。我们展示了non-local modeling在视频分类,目标检测,语义分割以及姿态估计中的重要性。在所有的任务中,简单的添加一个non-local blocks就可以在baseline上获得稳定的提升。我们希望non-local layers会成为未来网络结构中的一个重要组成部分。