论文阅读笔记6:Gradient Harmonized Single-stage Detector
论文地址:https://arxiv.org/pdf/1811.05181.pdf
代码地址:https://github.com/libuyu/GHM_Detection
Abstract
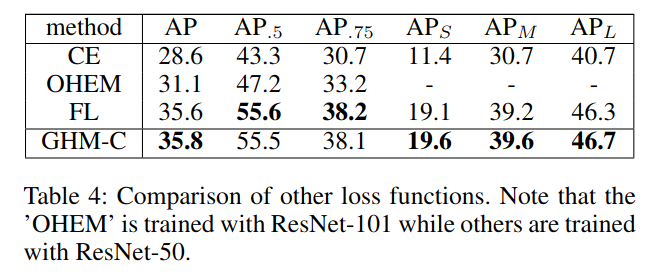
尽管单阶段的检测器速度较快,但在训练时存在以下几点不足,正负样本之间的巨大差距,同样,easy,hard样本的巨大差距。本文从梯度角度出发,指出了上面两个不足带来的影响。然后,作者进一步提出了梯度协调机制(GHM)用于避开上面的不足。GHM的思想可以嵌入到用于分类的交叉熵损失或者用于回归的Smooth-L1损失中,最后,本文修改过的损失函数GHM-C与GHM-R用于平衡anchor分类及回归二者的梯度。提出的`模型在COCO测试集上的mAP达到了41.6,与$Focal Loss(FL)+SL_{1}$相比,超过了0.8。
Introduction
但阶段检测器在训练时面临的最具挑战性的问题就是easy和hard样本以及positive和negative样本之间的严重不平衡。巨大数量的easy以及背景样本影响了检测器的训练。归功于proposal-driven机制,这个问题在二阶段检测器中并不存在。后来,出现了基于OHEM的样本挖掘技术,但这种方法舍弃了大部分样本,训练也不是很高效,后来Focal Loss通过修改损失函数来调整不平衡问题。但是Focal loss引入了两个超参数,需要进行大量的实验进行调试,同时,Focal loss是一种静态损失,对数据集的分布不敏感,而在训练过程中,数据集的分布是会发生变化的。
本文指出类别不平衡主要归结于难度的不平衡,而难度的不平衡可以归结为,gradient norm分布的不平衡。如果一个正样本很容易被分类,则该样本为easy example同时模型从中得到的信息量较少,比如,通过这个样本,只产生了一点梯度信息。模型应该关注这个被分错的样本无论它属于哪个类别。从整体上来看,负样本易于多为easy examples,而hard examples通常为为正样本。因此,两种不平衡可以归结为属性上的不平衡。
此外,上面两种类型的不平衡(hard/easy , positive/negative)可以由gradient norm的分布表示。带有gradient norm的样本密度,被称为梯度密度,如下图左侧所示,由于存在大量的简单负样本,gradient norm较小的样本的密度很大。虽然一个简单样本对整体的梯度贡献很小,但大量的简单样本作用后会占据训练的主导,使训练过程并不是很高效。另外我们发现gradient norm较大的样本(hard examples)的密度也大于中间样本的密度。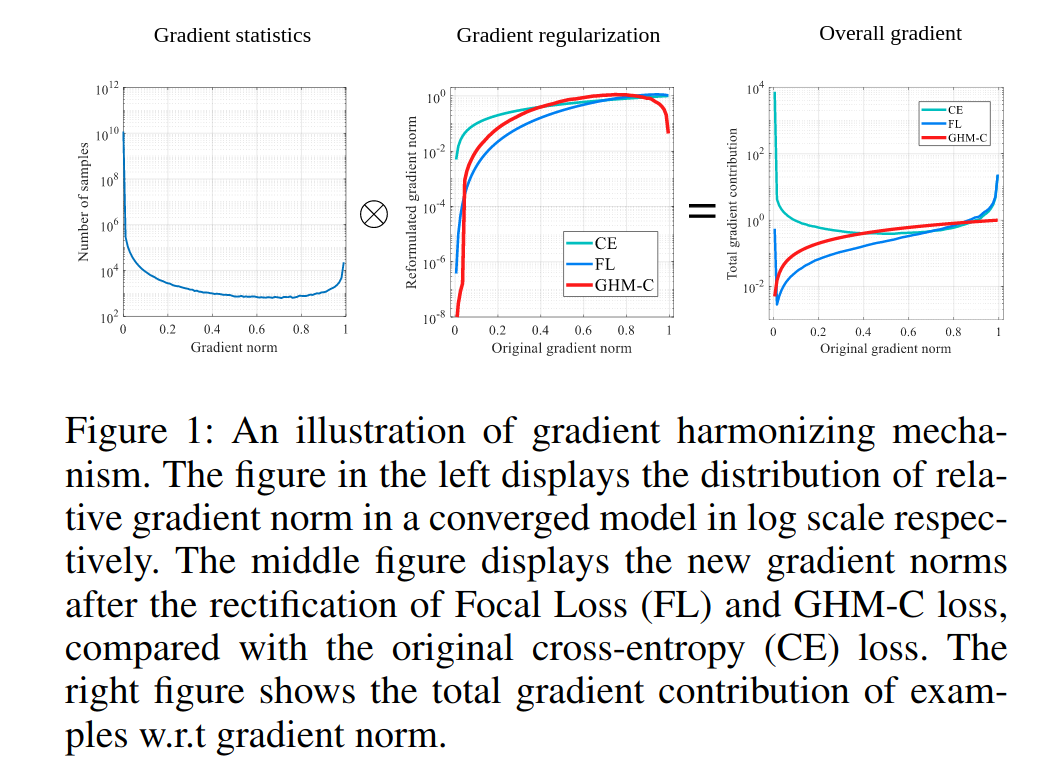
得益于对gradient norm的分布的分析,我们提出了一个 gradient harmonizing mechanism (GHM)来高效的训练单阶段的目标检测模型,这个机制着重于不同样本的梯度分布的harmony。GHM先统计具有相似梯度密度的样本的数量,对每一个样本根据其密度添加一个harmonizing参数。使用GHM来训练,每种样本的分布会趋于平衡,训练过程会变得更高效和稳定。
在实验中,对梯度的改变可以通过对损失函数的重新设计来等效的实现。我们把GHM嵌入分类损失,命名为GHM-C损失,同样我们也在回归分支中使用了GHM,命名为GHM-R损失。
我们的最主要贡献:
- 我们揭示了单阶段检测器在gradient norm分布方面存在显著不足的基本原理,并且提出了一种新的梯度平衡机制(GHM)来处理这个问题。
- 我们提出了GHM-C以及GHM-R,它们纠正了不同样本的梯度分布,并且对超参数具有鲁棒性。
- 通过使用GHM,我们可以轻松地训练单阶段检测器,无需任何数据采样策略,并且在COCO基准测试中取得了state-of-the-art的结果。
Related Work
- Object Detection
- Object Function for Object Detector
Gradient Harmonizing Mechanism
Problem Description
对于一个候选框,它的真实标签为$p^{*}\in\lbrace0,1\rbrace$,预测的值为$p\in[0,1]$,采用二元交叉熵损失:
假设$x$为模型输出,使得$p=sigmoid(x)$,那么上述的交叉熵损失对$x$的导数为:
那么梯度的模定义为:
$g$代表了这个样本的难易程度以及它对整个梯度的贡献。
下图是一个收敛模型的梯度模长的分布,可以看出简单样本的数量很大,使得它对梯度的整个贡献很大,另一个需要的地方是,在梯度模较大的地方仍然存在着一定数量的分布,说明模型很难正确处理这些样本,作者把这类样本归为离群样本,因为他们的梯度模与整体的梯度模的分布差异太大,并且模型很难处理,如果让模型强行去学习这些离群样本,反而会导致整体性能下降。
Gradient Density
训练样本的梯度密度函数为:
其中$g_k$为第$k$个样本的gradient norm。
g的gradient norm即为在以g为中心,长度为$\epsilon$的区域内的样本数,并且由该区域的有效长度进行归一化。
现在我们就可以定义梯度密度harmonizing参数:
$N$为样本总数
GHM-C Loss
根据梯度密度harmonizing参数,就可以得到损失函数的梯度密度harmonized的形式:

上图对比了不同损失函数下的gradient norm的分布。可以看出,之前提到的简单样本的权重得到了较大幅度地降低,离群样本也得到了一定程度的降权。使用经过改善之后的损失函数使得训练过程更加高效和鲁棒。
Unit Region Approximation
Complexity Analysis
常规计算所有样本梯度值的算法复杂度为$O(N^2)$,即使使用并行计算,每个计算节点仍有N的计算量。比较好的算法首先会以$O(NlogN)$的复杂度通过梯度正则对样本进行排序,然后使用一个队列来扫描样本,以$O(N)$的方式得到密度。由于单阶段检测中的N为$10^5$或者$10^6$,其梯度计算量仍很大,基于排序的算法比并行计算提升的幅度有限。本文提出了近似的获得样本梯度密度的方法。
Unit Region
我们把$g$的分布空间分为长度为$\epsilon$的独立unit区域,所以共有$M=\frac{1}{\epsilon}$个区域。让$r_j$表示第$j$个区域,那么$r_j=[(j-1)\epsilon,j\epsilon)$。让$R_j$表示在$r_j$区域里的样本个数。我们定义$ind(g)=t$,表示$g$所在的区域的序号,满足$(t-1)\epsilon<=g<t\epsilon$。
然后我们定义近似梯度密度函数:
然后我们就得到了近似梯度密度harmonizing参数:
最后我们得到了重新制定的损失函数:
EMA
基于Mini-batch统计的方法存在一个问题:当一个mini-batch中存在大量的异常点时,统计结果为噪声,而且使训练变得不稳定。Exponential moving average(EMA)是解决此问题的常用方法,比如带动量的SGD及BN处理。由于梯度密度的近似计算中的样本来自于单元区域,因此可以在每个单元区域应用EMA,进而得到更多稳定的梯度密度。
GHM-R Loss
Smooth L1损失函数为:
由于$d=t_i-t_i^*$,smoothL1 loss关于$t_1$的导数为:
对于所有$|d|>\delta$的样本,都具有相同的gradient norm$|\frac{\partial SL_1}{\partial t_i}|=1$。这就不可能仅仅依靠gradient norm来区分不同属性的样本。一个选择就是直接使用$|d|$作为不同属性的度量。但新的问题是$|d|$理论上可以达到无穷大,单位区域的近似无法实现。
为了便捷的在回归loss上应用GHM,我们把传统的$SL_1$loss改变为更优雅的形式:
当$d$很小时,近似为一个方差函数(L2 loss),当$d$很大时近似为一个线性损失(L1 loss),称该损失为Authentic Smooth L1损失,具有很好的平滑性,其偏导存在且连续。&ASL_1$的偏导如下:
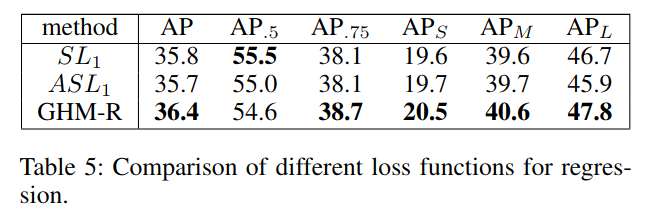
我们定义$gr=|\frac{d}{\sqrt{d^2+{\mu}^2}}|$为$ASL_1$loss的gradient norm,其梯度分布如下图所示,从图中可以看出存在大量的异常点。而回归损失只作用在正样本中,因此,分类与回归的分布是不同的。最后,将GHM应用于回归loss:

我们强调,在边框回归中并不是所有的“简单样本”都是不重要的。在分类中一个简单样本通常是一个背景区域,有着很低的预测可能值,会被排除在最终候选框外。因此对这些样本的改进并不会对精度产生任何的影响。但是在边框回归中一个简单样本仍然偏离了真实框位置。对每个样本更好的预测会直接提升最终候选框的质量。而且,高级的数据集更关心定位的精确性
我们的GHM-R能够harmonize简单样本以及困难样本对边框回归的贡献,通过对简单样本的重要部分进行升权,以及对离群样本进行降权。实验显示它能比$SL_1$一级$ASL_1$获得更好的性能。
Experiments