论文阅读笔记5:CenterNet:Keypoint Triplets for Object Detection
论文地址:https://arxiv.org/abs/1904.08189
代码地址:https://github.com/Duankaiwen/CenterNet
Abstract
目标检测中,基于关键点的方法经常出现大量不正确的边界框,主要是由于缺乏对相关剪裁区域的额外监督造成的。本文提出一种有效的方法,以最小的资源探索剪裁区域的视觉模式。本文提出的CenterNet是一个单阶段的关键点检测模型。CenterNet通过检测每个目标物看作是一个三个关键点,而不是一对关键点,这样做同时提高了准确率及召回率。本文还设计了另外两个模型,cascade corner pooling及center pooling,容易获得从左上角及右下角的丰富信息,同时在中间区域获得更多的识别信息。在MS-COCO数据集中CenterNet的AP达到了47.0%。
Introduction
本文改进了CornerNet,增加了一个观察每个候选区域的视觉模式的功能,进而可以判断每个边界框的正确性。CenterNet通过增加一个关键点来探索proposal中间区域(近似几何中心)的信息,本文创新点在于,如果预测的边界框与ground truth有较高的IoU,则中心关键点预测出相同类别的概率要高,反之亦然。因此,在进行inference时,当通过一组关键点产生了一个边界框,我们继续观察是否具有同类别的一个关键点落入区域的中心,即使用三个点表示目标。
为了更好的检测中心的关键点即角点,提出了两个方法来丰富中心点及角点的信息。
- center pooling:用于预测中心关键点的分支,有利于中心获得更多目标物的中心区域,进而更易感知proposal的中心区域。通过取中心位置横向与纵向响应值的和的最大值实现此方法。
- cascade corner pooling:增加原始的corner pooling感知内部信息的功能。结合了feature map中目标物内部及边界方向的响应值和的最大值来预测角点。经试验证实,此方法在存在feature-level 噪声的情况下更加稳定,有助于准确率及召回率的提升。
Related Work
- Two-stage approaches
把目标检测task分为两个stages:提取RoIs,然后对RoIs进行分类和回归。 - One-stage approaches
移除RoI提取步骤,直接对候选的anchor boxs进行分类和回归
Our Approach
baseline and Motivation
本论文的 baseline 为 CornerNet,因此首先讨论 CornerNet 为什么容易产生很多的误检。首先,CornerNet 通过检测角点确定目标,而不是通过初始候选框 anchor 的回归确定目标,由于没有了 anchor 的限制,使得任意两个角点都可以组成一个目标框,这就对判断两个角点是否属于同一物体的算法要求很高,一但准确度差一点,就会产生很多错误目标框。其次,恰恰这个算法有缺陷。因为此算法在判断两个角点是否属于同一物体时,缺乏全局信息的辅助,因此很容易把原本不是同一物体的两个角点看成是一对角点,因此产生了很多错误目标框。最后,角点的特征对边缘比较敏感,这导致很多角点同样对背景的边缘很敏感,因此在背景处也检测到了错误的角点。综上原因,使得 CornerNet 产生了很多误检。
我们分析出了 CornerNet 的问题后,接下来就是找出解决之道,关键问题在于让网络具备感知物体内部信息的能力。一个较容易想到的方法是把 CornerNet 变成一个 two-stage 的方法,即利用 RoI pooling 或 RoI align 提取预测框的内部信息,从而获得感知能力。但这样做开销很大,因此我们提出了用关键点三元组来检测目标,这样使得我们的方法在 one-stage 的前提下就能获得感知物体内部信息的能力。并且开销较小,因为我们只需关注物体的中心,从而避免了 RoI pooling 或 RoI align 关注物体内部的全部信息。
Object Detecton as Keypoint Triplets
网络通过 center pooling 和 cascade corner pooling 分别得到 center heatmap 和 corner heatmaps,用来预测关键点的位置。得到角点的位置和类别后,通过 offsets 将角点的位置映射到输入图片的对应位置,然后通过 embedings 判断哪两个角点属于同一个物体,以便组成一个检测框。正如前文所说,组合过程中由于缺乏来自目标区域内部信息的辅助,从而导致大量的误检。为了解决这一问题,CenterNet 不仅预测角点,还预测中心点。我们对每个预测框定义一个中心区域,通过判断每个目标框的中心区域是否含有中心点,若有则保留,并且此时框的 confidence 为中心点,左上角点和右下角点的confidence的平均,若无则去除,使得网络具备感知目标区域内部信息的能力,能够有效除错误的目标框。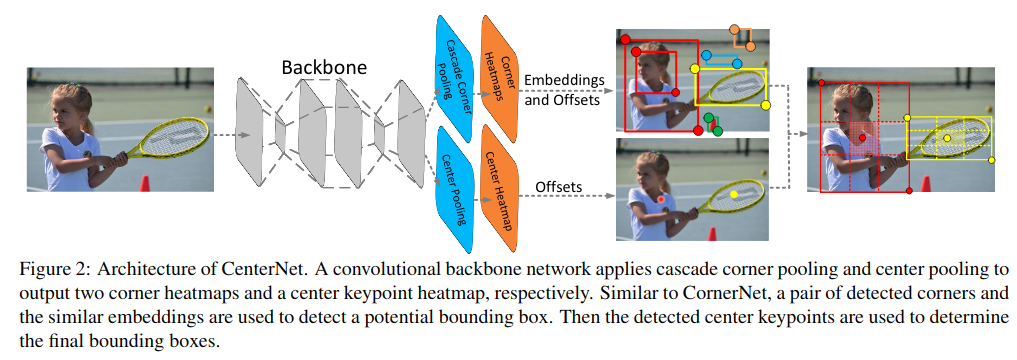
我们发现中心区域的尺度会影响错误框去除效果。中心区域过小导致很多准确的小尺度的目标也会被去除,而中心区域过大导致很多大尺度的错误目标框无法被去除,因此我们提出了尺度可调节的中心区域定义法。
该方法可以在预测框的尺度较大时定义一个相对较小的中心区域,在预测框的尺度较小时预测一个相对较大的中心区域。如图所示。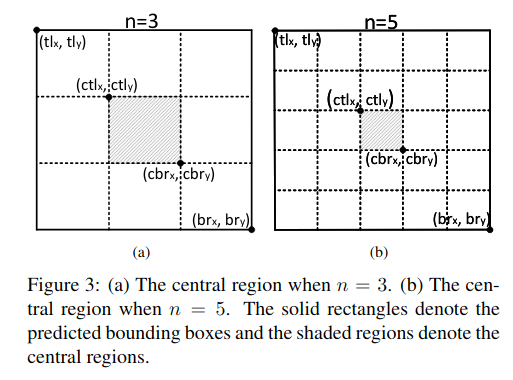
$n$决定了中心区域的尺度。在本文中,对于尺度小于或者大于150的边界框,$n$分别取值为3或5。
Enriching Center and Corner Information
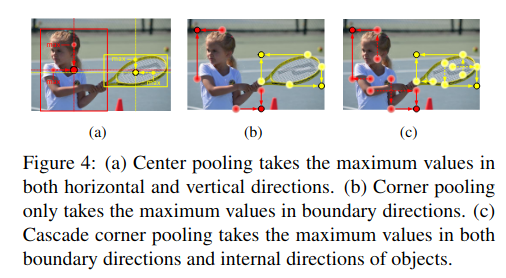
- Center pooling
一个物体的中心并不一定含有很强的,易于区分于其他类别的语义信息。例如,一个人的头部含有很强的,易于区分于其他类别的语义信息,但是其中心往往位于人的中部。我们提出了center pooling 来丰富中心点特征。center pooling提取中心点水平方向和垂直方向的最大值并相加,以此给中心点提供所处位置以外的信息。这一操作使中心点有机会获得更易于区分于其他类别的语义信息。Center pooling 可通过不同方向上的 corner pooling 的组合实现。一个水平方向上的取最大值操作可由 left pooling 和 right pooling通过串联实现,同理,一个垂直方向上的取最大值操作可由 top pooling 和 bottom pooling通过串联实现 - Cascade corner pooling
一般情况下角点位于物体外部,所处位置并不含有关联物体的语义信息,这为角点的检测带来了困难。传统做法 corner pooling,它提取物体边界最大值并相加,该方法只能提供关联物体边缘语义信息,对于更加丰富的物体内部语义信息则很难提取到。cascade corner pooling 首先提取物体边界最大值,然后在边界最大值处继续向内部(图中沿虚线方向)提取提最大值,并与边界最大值相加,以此给角点特征提供更加丰富的关联物体语义信息。Cascade corner pooling 也可通过不同方向上的 corner pooling 的组合实现。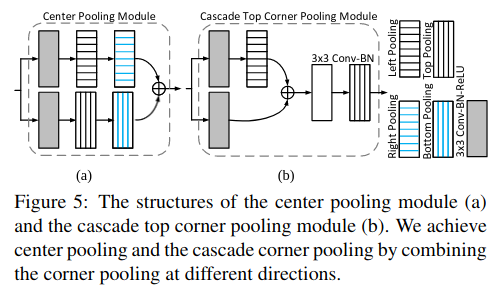
Training and Inference
- Training 输入图像的分辨率为512×512,heatmaps的大小为128×128,我们使用数据增强来训练一个鲁棒的模型。用Adam来优化训练的损失:
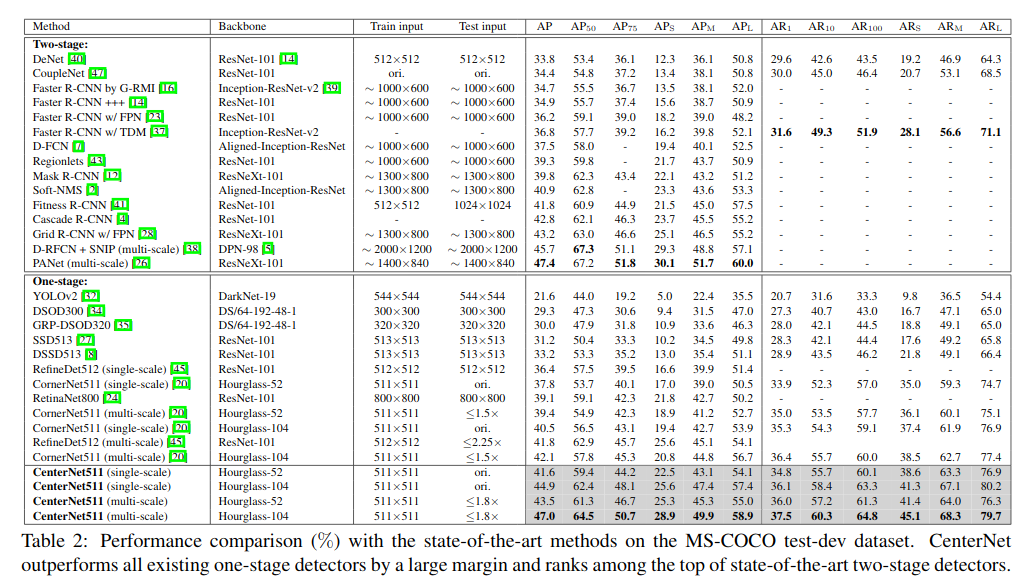
Experiments
- Comparisons with State-of-the-art Detectors