论文阅读笔记3:Selective Kernel Networks
论文地址:https://arxiv.org/pdf/1903.06586.pdf
论文代码:https://github.com/implus/SKNet
Abstract
在标准的卷积网络中,每层网络中神经元的感受野的大小都是相同的。在神经学中,视觉神经元感受野的大小是由刺激机制构建的,而在卷积网络中却很少考虑这个因素。本文提出的方法可以使神经元对于不同尺寸的输入信息进行自适应的调整其感受野的大小。building block为Selective Kernel单元。其存在多个分支,每个分支的卷积核的尺寸都不同。不同尺寸的卷积核最后通过softmax进行融合。分支中不同注意力在fusion layer产生不同的有效感受野。多个SK单元进行堆叠构成Selective Kernel Networks (SKNets)。详细分析显示SKNet里的神经元可以根据输入通过适应性的调整感受野的大小来捕捉不同尺度的目标object。
Introduction
在上世纪猫的前视觉皮层神经元的局部感受野激发了卷积网络的产生。在视觉皮层中,相同区域的神经元的局部感受野的大小是不同的,从而可以在相同的处理阶段中获得不同尺寸的空间信息。该思想被Inception系列网络完美的应用,在其building block中,3x3,5x5,7x7的卷积通过简单的拼接来得到多尺寸信息。
然而,在设计卷积网络时,神经元感受野的其他属性并没有被考虑到。比如感受野尺寸的自适应调整。大量实验证明,视觉皮层的神经元的感受野尺寸并不是固定的,而是受激励调制的。像Inception这种具有多个分支的网络其内部存在一种潜在的机制可以在下一个卷积层根据输入的内容调整神经元感受野的大小,这是因为下一个卷积层通过线性组合将不同分支的特征进行融合。但是线性组合的方法不足于提供网络强大的调整能力。
本文提出了一种非线性的方法聚合来自不同核的特征进而实现感受野不同尺寸的调整。引入了”Selective Kernel”卷积,其包含了三个操作:Split,Fuse,Select:
- Split操作产生多个不同核尺寸的通道对应于神经元的不同感受野尺寸。
- Fuse操作组合融合来自多通道的信息从而获得一个全局及可理解性的表示用于进行权重选择。
- Select操作根据挑选得到的权重对不同核尺寸的feature map进行融合。
Related work
- Multi-batch convolutional network
- Highway network
- ResNet
- FractalNets and Multilevel ResNets
- TnceptionNets
- Grouped/depthwise/dilated convolutions
- Grouped convolution 减少了参数个数以及计算成本,首次应用于AlexNet。使用grouped convolution,ResNeXts也能够提升准确率。
- Depthwise convolution grouped convolution的特殊情况,groups的个数等于通道的个数。
- Dilated convolutions 可以指数式扩大感受野,而且不会loss of coverage。
在SK convolution中,大尺寸的卷积核被设计成grouped/depthwise/dilated convolutions的集合,来避免沉重的开销。
- Attention mechanisms
设计一系列的注意力分配系数,也就是一系列权重参数,可以用来强调或选择目标处理对象的重要信息,并且抑制一些无关的细节信息。 - Dynamic convolutions
- Dynamic Filter 只能适应性的改变filters的参数而不是卷积核大小的调整
- Active Convo-lution 使用偏移来增强卷积中的位置采样
- De-formable Convolutional Networks 动态地产生位置偏移
Methods
Selective Kernel Convolution
SK convolution 包含三个操作——Split,Fuse以及Select,如下图所示: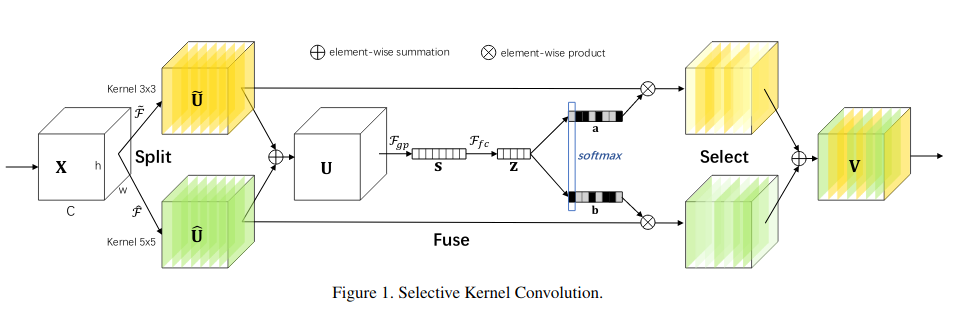
在这个例子中由两个分支,因此只有两个不同的卷积核,单它很容易拓展成多个分支。
Split:给定feature map $X\in R^{H^{‘}×W^{‘}×C^{‘}}$,我们先执行两个卷积核大小分别为3和5的变换$\overline{T}:X\rightarrow \overline{U}\in R^{R×W×C}$以及$\hat{T}:X\rightarrow \hat{U}\in R^{R×W×C}$两种变换都是由一系列高效的grouped/depthwise convolution,Batch Normalization以及ReLU函数组成。为了更加高效,55的卷积核由33空洞为2的空洞卷积代替。
Fuse:基本的想法是使用gates来控制来自多个分支的带着不同尺度信息的information流入下一层的神经元。为了实现这个目标,gates需要聚合来自所有分支的information。我们首先通过一个逐元素的summation:
然后我们编码这个全局信息通过全局平均池化来生成逐通道的统计量$s\in R^{C}$s中的第c个元素通过在U的HxW维度上进行压缩计算得到:
然后产生一个用于指导精确性以及适应性选择的紧凑的feature$z\in R^{d×1}$。通过一个全连接层得到,同时,进行了降维处理:
$\delta$为ReLU函数,B为Batch Normalization。为了验证W中d的作用,引入了一个衰减率r,如下,其中C代表通道数,L为d的最小值。
Select:通道间的soft attention可以选择不同尺寸的信息,其被紧凑的特征信息Z引导。在channel-wise应用softmax操作。
$A,B\in R^{C×d}$,个人理解矩阵A和B就是两个全连接的权值矩阵,这里就存在一个疑问,那么生成向量z的意义是什么,可以直接在向量s上做全连接。向量a和b分别为$\overline{U}$以及$\hat{U}$的soft attention vector。$A_{c}$为矩阵A的第c行,$a_{c}$为向量a的第c个元素。在两个分支的情况中,矩阵B是多余的,因为$a_{c}+b_{c}=1$。最后的feature map$V$通过不同卷积核的注意力权重得到:
$V=[V_{1},V_{2},…,V_{C}],\quad V_{c}\in R^{H×W}$
Network Architecture
和ResNeXt类似,SKNet也主要由一堆名为“SK unit”的repeated bottleneck blocks组成。每一个SK unit由11的卷积,SK卷积以及11卷积组成。ResNeXt中所有具有较大尺寸的卷积核都替换为SK卷积,从而可以使网络选择合适的感受野大小。
在SK单元中,存在三个重要的超参数,来决定SK卷积的最终设置:
- 路径的数量M,决定了聚合多少种不同尺寸的卷积核。
- 组数G,控制每一条路径的基数
- 衰减率r,控制在fuse操作中参数的个数
网络结构如下:
Experiments

