论文阅读笔记1:RepPoints:Point Set Representation for Object Detection
论文地址:https://arxiv.org/abs/1904.11490
论文代码:未公布
Abstract
当前主流的目标检测网络,对于bounding box的依赖很严重,无论是one-stage还是two-stage的检测器,都需要bounding box对目标区域进行提取,划分,然后进行分类和回归。但是这些bounding box都是规则且相对固定的候选框,只能对目标提供一个较为粗糙的定位,这就导致bounding box提取出来的特征也是粗糙的。本文提出了RepPoints(representive points),通过一组有代表性的点,实现对目标的更精细表示,对于后续的分类和定位都有帮助。在训练过程中,给定Ground Truth的位置和识别目标,RepPoints学会自动排列代表性点,限定目标的空间范围,并表示语义上重要的局部区域。整个过程都不需要anchor进行bounding box的采样,是名副其实的anchor-free。实验表明,基于RepPoints的网络结构,在没采用多尺度训练的情况下,在COCO数据集上,AP指标上达到了42.8%。
Introduction
目标检测一直是计算机视觉中的基础且热门领域,为诸如分割,跟踪等任务提供辅助。随着深度学习的迅速发展,目标检测网络取得了迅速的发展进步,代表性网络如Faster R-CNN, YOLO,Ssd等都有很好的表现。纵观所有的目标检测网络,都绕不开bounding box的存在,bounding box包围图像的目标区域,作为整个目标检测中的基本处理单元。基于提取的bounding box,进一步进行分类和位置回归处理。bounding box的应用很大程度源于网络结构的评价指标,即预估框和GT框的重叠覆盖程度。还有一个原因是因为bounding box这种规则的形状对特征提取和后续的池化处理提供了便利。虽然如此,但是bounding box只是对目标的粗糙提取,这种提取可能并不符合目标的姿态和形状,因此提取出来的内容势必会包括一些背景信息等无关信息,这可能会产生较低质量的特征,从而影响目标检测的分类性能。
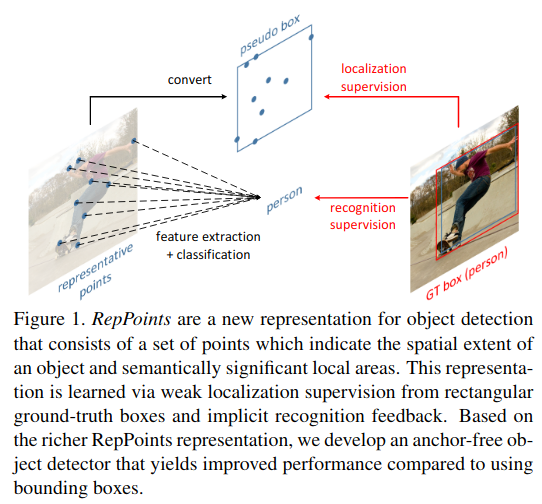
本文提出了一种全新的方法RepPoints,通过一组点集提供更细粒度的位置表示和便于分类的信息。如下图所示:RepPoints是一系列点组成的集合,这些点分布在目标的空间范围和具有重要语义信息的位置。RepPoints的训练由目标定位和识别共同驱动,RepPoints与GT bounding box紧密结合,引导检测器正确分类目标。这种方法摆脱了bounding box的限制,更没有了anchor的烦恼。
为了证明ReoPoints的强大,本文利用一个可变形卷积实现了目标检测网络,该网络在保持特征提取方便的同时,提供了适合于指导自适应采样的识别反馈。接下来会有详细介绍。
Related Work
Bounding boxes for the object detection problem
Bounding box流行的主要原因有:- Bounding box可以很便捷的进行注释而且几乎没有歧义,同时在最后的认知阶段可以提供高效的进准定位。
- 不管是过去,还是在深度学习领域,几乎所有的图片特征提取都是以网格的形式作为输入。因此,应用bounding box可以很方便的促进特征提取
Bounding boxes in modern object detectors
bounding box表示出现在多阶段识别模式的几乎所有阶段:1)作为anchors。2)作为object proposals。3)作为最终的localization targets。
Other representations for object detection
最近的目标检测Bottom-up approaches:- CornerNet 预测左上以及右下的角点,应用专门的grouping方法来获得object的bounding box
- ExtremeNet 定位object在x和y方向上的极点来预测bounding box
Deformation modeling in object recognition
The RepPoints Representation
Bounding Box Representation
- Review of Multi-Stage Object Detectors
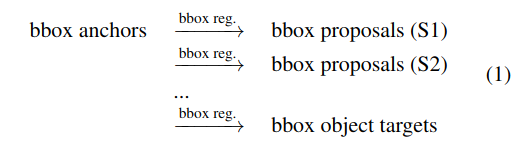
- Bounding Box Regression
边界框回归的过程不再赘述
RepPoints
正如前面讨论的,4-d的bounding box是目标位置的粗糙表达,边界框只考虑目标的矩形空间范围,不考虑形状、姿态和语义上重要的局部区域的位置,但恰恰是这些区域,可用于更好的定位和更好的对象特征提取。为了克服这些局限,RepPoints建立一组自适应的特征点集$R\in\lbrace(x_{k},y_{k})\rbrace_{k=1}^{n}$其中n是构成点集的点数量,在本文中,n被设置为9,也就是抽样9个点
RepPoints refinement
对R中的每一个点预测一组偏移$\lbrace(\Delta x_{k},\Delta y_{k})\rbrace_{k=1}^{n}$。因此refinement的过程就可以简单的表示为:$R_{r}=\lbrace(x_{k}+\Delta x_{k},y_{k}+\Delta y_{k})\rbrace$Converting RepPoints to bounding box
得到一组点后,接下来就把这些点转化为bounding box ,我们定义一个转换函数T:$R_{p}\rightarrow B_{p}$,
$R_{p}$为object $P$的RepPoints,$B_{p}$表示一个pseudo box,转换函数有三种形式:- T=T1:Min-max function. 在x,y两个坐标轴方向上,寻找点集中的极值点来表示bouning box,一般来说,有两个点就能构成一个bounding box
- T = T2: Partial min-max function. 先从点集中选取相应的子集,将选取出的点利用(1)式方法,构成bounding box
- T = T3: Moment-based function.计算点集中所有点的均值作为bounding box的中心点坐标,二阶矩作为bounding box的宽和高。“矩”是一组点组成的模型的特定的数量测度,关于二阶矩,可以简单理解为随机变量的方差。
Learning RepPoints
RepPoints的学习是目标定位损失以及目标认知损失共同驱动的。关于目标定位的损失,需要我们利用上文中提到的转换函数T生成一个pseudo box,然后利用bounding box和GT bounding box进行运算。在本文中,作者在左上角和右下角之间的距离运用smooth L1,进行位置回归。
RPDet: an Anchor Free Detector
为了验证利用RepPoints代替bounding box候选的可行和强大,设计了一个anchor-free的网络结构,整个网络是由两个基于可变形卷积的识别阶段组成。作者将RepPoints和可变形卷积很好的结合起来。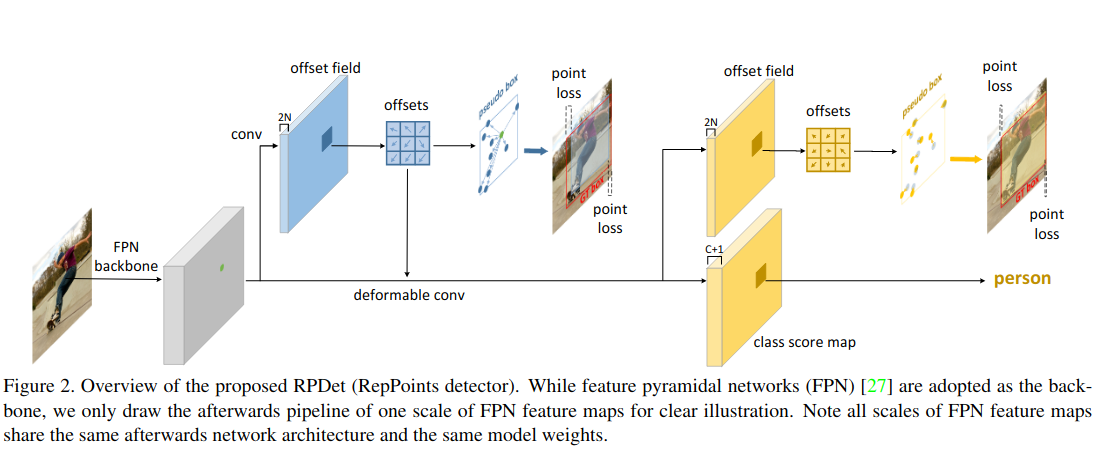
目标表示的演化过程: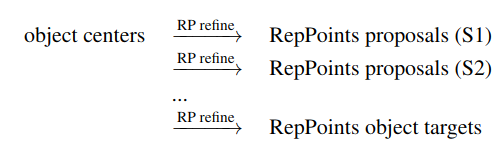
Center point based initial object representation
我们和YOLO和DenseBox一样使用中心点作为ojects的初始表示,使之成为一个anchor-free的目标检测器。中心点表示的一个重要好处就是它的假设空间相比于anchor-based更tight。Utilization of RepPoints
the first set of RepPoints通过一个常规的3*3卷积得到,这些RepPoints的学习由两个objectives驱动:- pseudo box和ground-truth bbox之间的左上以及右下角点的距离loss
- 随后阶段的认知loss
the second set of RepPoints表示最终的object定位,只由点之间的距离loss驱动。
Other details
不再叙述
Deformable Convolution
研究发现,标准卷积中的规则采样格点采样是导致网络难以适应几何形变的“罪魁祸首”,为了削弱这个限制,对卷积核中每个采样点为位置都增加一个偏移量,可以实现在当前位置附近随意采样而不局限于规则的格点,如下图是常见的采样点和可变形卷积采样点的对比。其中(a)是规则的采样点,(b)(c)(d)是在规则采样点的基础上,加上一个偏移量,使得采样点的位置发生变化

可变形卷积的目的是提升形变的建模能力。通过可变形卷积(deformable conv)和可变形感兴趣区域池化(deformable ROI Pooling)这两个模块,基于一个平行网络学习一个偏移量(offset),使得卷积核在feature map上的采样点发生偏移,集中于我们感兴趣的区域。我们可以用下列网络结构来看:以一个feature map作为输入,常规的采样点如绿框所示,是规则且局限的,而可变形卷积的做法是,增加一路网络,经过卷积之后,输出一个维度为2N的map,其中N是采样点数量,2N是说明学习x,y两个方向的偏移,这样,对于每一个原始的采样点,我们都学习到了它在x,y两个方向上的偏移,即下图offsets map,指示了原始的采样点在融合x,y两个方向的偏移量后,最终的偏移方向。然后,将原始采样点与offset对应融合,得到最终采样位置,经过卷积运算,得到输出feature map上的结果。
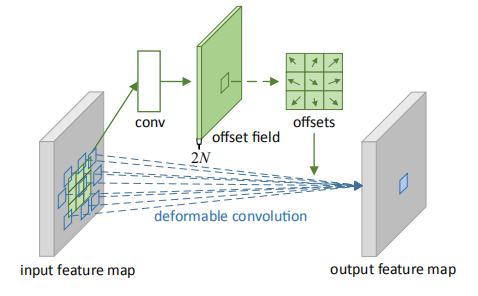
非常需要注意的一个点是,可变形卷积的可变形体现在采样点不是局限规则的,而不是卷积核是可变形的